I often see developers solving content challenges with the data-oriented principles. This is fundamentally wrong, like writing a sentence using letters instead of words. Such data-solutions work - but only after educating the editor in database concepts. Our customers find DNN-solutions simpler than Wordpress - because of a paradigm shift which changes everything we do. I would love to help you to see the world in this way - here's an attempt at it…
Data Versus Content
Since most DNN web designers and developers know databases and tables, you probably know what data is. What you're probably not aware of is that content is more like knowledge - it's data + meaning + context. In terms of a CMS this means that:
- Data is raw, table-style lists of information - think of lists of records/entities/content-items where the selection of what should the user see will be determined by the software - interactively, or pre-defined by the editor
- Content is consciously arranged data - comparable to knowledge - think of a normal web page, lovingly created by an author - where the selection and sequence of what the user should see was deliberately created to assemble meaning
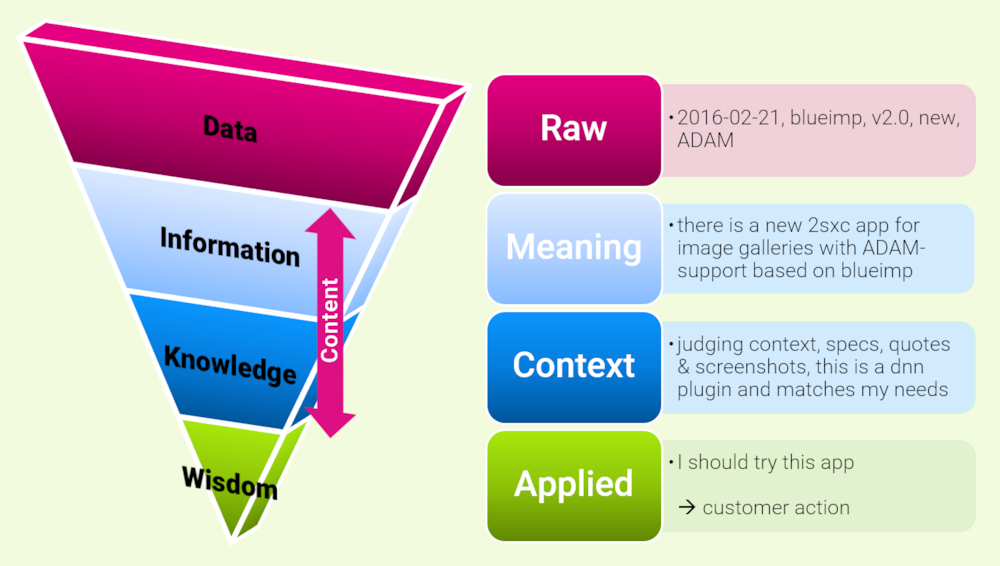
Note that data can be used as content, and content can be used as data. When you create data to describe a specific image on the image-slider you use it as content. And if you create a page listing all images on the site, together with the their descriptions then you are using previously created content as if it were data. A blog post is content, assembled manually, while the list-of-all-posts-with-the-tag-2sxc is data.
Completely Different Editorial Challenges
Here's a simple example where the same task is solved differently depending on the data/content focus: Imagine a web site showing various services and presenting faces of the preferred contact person on each page.
- The Data Approach would create a list of contact persons, assign categories related to the services and then create view-components which "show all persons with category X, sorted by seniority" which will be added to each page as needed. The idea is "manage a list of persons, and the output should happen automatically using categories".
- The Content Approach would create a "show one or more persons" module which the editor adds to a page, and then fills in with the persons profile. The editor will add some persons or possibly pick persons to display which he had already created previously. The idea is "the editor builds the content step-by-step and selects what should appear, and in what sequence"
What's really important is that the editor is forced to think in data-models (lists of contacts, automatic filters, automatic sorting) in the first case, while the second case is a straightforward editing process (show this here, that there).
Example with 300+ FAQs and Hundreds of Documents
I would like to demonstrate a typical scenario we implemented for the Swiss Social Security (AHV-IV). It has hundreds of FAQ-style items (yea! a table…or not?) and hundreds of downloadable documents stored with structured metadata. The data used for the documents is ideal for a table, and it's needed in various places - even for short-urls and QR-codes, so the data related to the document even has an impact on IIS-routing rules. Normally the solution would have been to create a database with the documents and then provide various view-modules to place them in the right spot.
Our solution was to not create a document database. We implemented it as a content. The user experience is to create a page, add questions and documents to that page, and her work is done. In the background, the content is of course managed in structured tables, but the user's experience is content - and the user could also break out and add a gallery or whatever at any time.
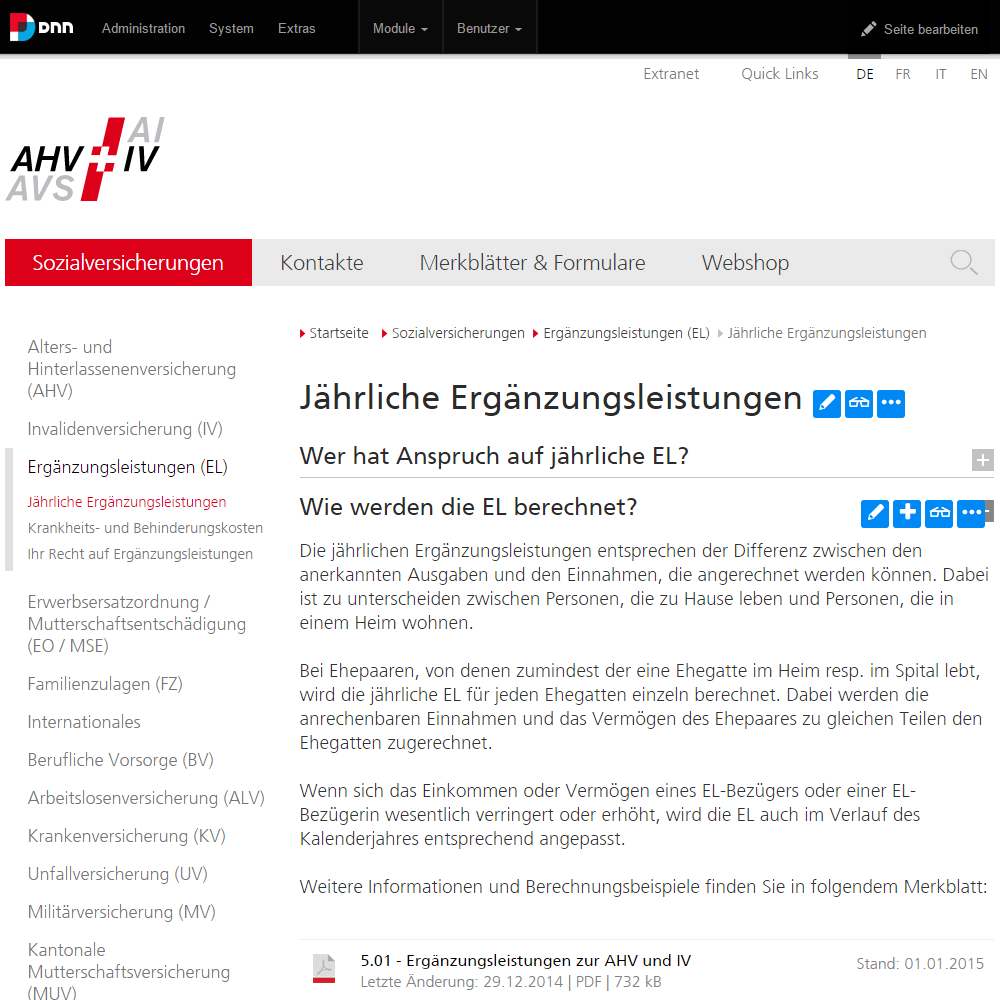
So while the user is creating pages, content and adding documents, the data is automatically categorized for further use. In the second phase there came the need to create consolidated lists of these documents - like this:

…but as you can see, the user perception is "I create content anywhere - and it's automatically available in the list-view as well". This is much easier to work with, than "I manage lists of documents and FAQs, categorize them correctly, give them priorities and hope that they appear in the right places and in the right order"
Same Technology, very Different Editor Experience
You'll note that both approaches demonstrated above will internally have structured data (person profiles) and structured output (face here, name there, phone-number…) but the concept makes a world of a difference to the editor.
Just to be clear again what the difference is
- The Data Paradigm starts by giving the editor a structured list of information to manage, and the output is handled separately, usually as a form of "extract" from the original data. It's easy to spot when you plan to train the user and have to start with "Before we start, I need to explain how it works". So a common indicator is the thought that "it's a system, and as soon as the editor gets it, it's easy". It usually isn't easy, but the developer sees it that way.
- The Content Paradigm feels like the underlying data is just granted, the user doesn't need to think about it. The training-indicator is when you start you training with "This is how you add a product on this page - it's just like adding a picture, only with more fields". In content-mode the editor will focus page, page-layout and the current piece of content - and nothing else. It's the natural continuation of front-end-editing. When training the content-paradigm the user will often ask "but what if I need a list of these [people | products | questions | images]?" and the designer will say "don't worry about that, we can easily add that once you need it".
Summing it Up
In our world view, this focus on content and content-editing is a key part to providing solutions which make the editor and site owner really, really happy.
I hope this was inspiring :)
Love from Switzerland,
Daniel