 Form and List, or better its predecessor, the "User Defined Table" module, was designed for creating and maintaining lists. As the output can be controlled with templates, the module can be used for a lot of different scenarios: announcements, contact lists, recipes, glossaries, FAQs, guest books, comments, address list, map etc. In short, Form and List is a universal toolbox for lot of different use cases.
Form and List, or better its predecessor, the "User Defined Table" module, was designed for creating and maintaining lists. As the output can be controlled with templates, the module can be used for a lot of different scenarios: announcements, contact lists, recipes, glossaries, FAQs, guest books, comments, address list, map etc. In short, Form and List is a universal toolbox for lot of different use cases.
There is a downside on designing for flexibility; it is not optimized for performance. Data is dynamic; lists are not directly mapped to SQL tables. Instead data is serialized into a stream of field-value pairs, making it difficult to handle with SQL directly. You cannot query with simple SQL statements, and search don't benefit from indexes.
For a lot of uses cases this approach is just good enough, usually lists are small and contain only some dozen to a few hundreds of entries. But I have been reported much bigger setups. They usually start small, setup is fast and easy. Everything works well in the beginning. Then, after some time in production, the data grows up to several thousands of records, turning the experience into a nightmare. Asked in the forums we could only acknowledge that it is by design.
We did some tests with larger record sets in the past and were able to fix the worst effects for slowdowns. The last days I spent some time for more serious measurements. For better understanding I will sketch up the render pipeline of Form and List.
Render process
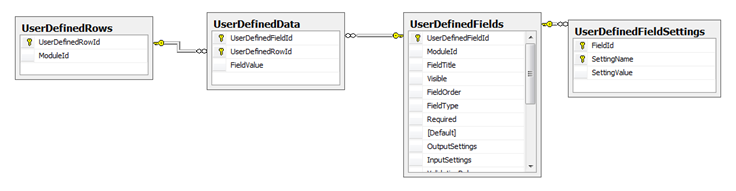
SQL Schema
- Each cell in Form and List is stored inside the table "UserDefinedData". Each record in that table holds the value as string and references to field and row. The value is saved into a column of type ntext (*).
- The table "UserDefinedFields" holds the schema of the list. It contains beside name and field type the most common properties. In addition, the table "UserDefinedFieldSettings" holds additional, but specialized information depending on the current field type.
- All data of a module instance is transferred by calling stored procedures and loading the content into a dataset with three DataTables: Fields, FieldSettings, and Data.
- On load the stream of field-value pairs is transferred and pivoted into the DataTable Data. Its columns map to the fields, and values are already converted to the matching system data type like String or Int.
-
Some Form and List types require special treatment:
- For example datetime values are stored in UTC, though they should be shown either in portal or user time. We also don't want to show a simple a simple 0 or 1 for a Boolean, instead a image of a checkbox, which is checked or not depending on the value, is shown.
- Certain types are returning references to pages/tabs or files, eg. fileid=1234. Information like name, path or download URL needs to retrieved with additional API calls.
- Other types like calculated column are executed on the fly, querying other columns
- Form and List adds hidden columns for any additional gathered information.
- Once all columns are created, the data table can be sorted or filtered against any column. This is a benefit of the old fashion dataset; it supported offline filter statements long time before Linq (to object).
- As a last step, the dataset or better the table data will be binded against a grid, or the dataset is converted into XML and XSL-transferred into Html.
In short:
GetData for module → Create a Dataset → Enrich the DataSet →Filter the Dataset -> Bind to Output
How many records are possible?
Now how does this perform? At first, let's start with a single custom field of data type text, filled with the string "text". The obligate audit fields created/changed by/at are also part of the module. I simply increased the numbers of records on each access by the factor 10. Here is the result:
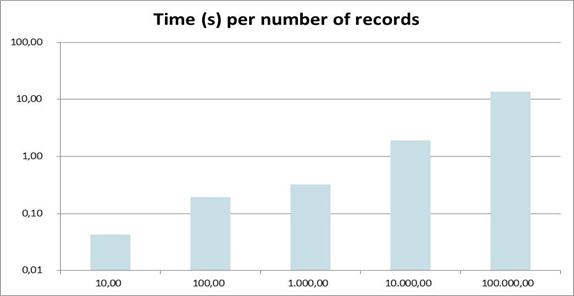
The x- axis shows the number of records, the y- axis the time needed.
Rendering time scales linear with the number of records. 10.000 records will take already about two seconds for rendering on my machine. This might be acceptable for small sites with only view visitors, but it will certainly cause trouble in a busy environment..
Influence of field type
Next, I've created a list which contains one field of each datatype. I added a few lines, made a module export, edited the XML copying the data section multiple times and imported it again. This resulted into a list of about 18.000 records. It takes more than 35 sec from page load to output. Now I was interested in the influence of the different parts of the render pipeline:
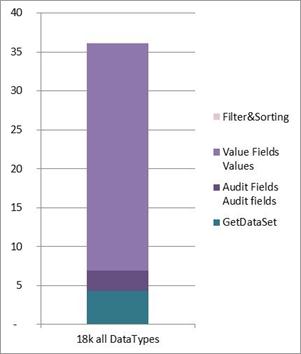
As you see, it takes already nearly 5 seconds to load this set from database into data table, but most time is spend in the treatment of the fields (5). Let's examine it in detail:
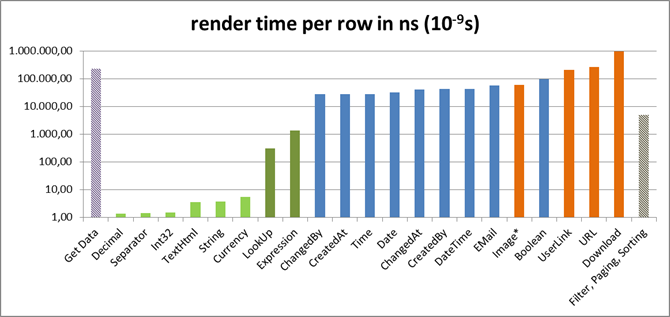
(Please note that the y-axis is exp10)
- The time for simple types
(strings and numbers) can safely be ignored. We are talking here about nano seconds.
- Value types which add hidden columns (5a) are taking some 10µs. If not written with performance in mind, even repeating calls to localization can cause lags.
- Reference types (5b) are calling API to retrieve more information, in worst case causing additional slow database calls. The Download already takes 0.1ms. The Image type has been even slower but was already optimized (**) for this setup.
- Calculated columns and Look-Ups are not that slow, at least for very simple expressions.
- Loading data takes its time and fits with its dimension to the first recording.
- Binding to a data grid or a XSL transformation (not in this recording) can be ignored, at least if they limit the amount of output for example with paging.
Result
- Form and List works very well with a limited number of records per module, enabling and solving a lot of use cases. It was never designed for bigger sets of data.
- There is no general answer about what a reasonable size is – it depends much on usage of different data types.
- If you store more than 1.000 records into a single Form and List, and the list is still growing, you might want to rethink your design.
Conclusion
I hope this examination will help you optimizing your Form and List handling. Question is whether this also helps to optimize the module itself. I've got a lot of proposals regarding performance in past, here are some ideas and my point of view:
- While System.Data.DataSet is slow, it is still the base of the module. If this is replaced by any IList and Linq, it will surly improve speed, but any filter or calculated column will be broken for sure. It would not be Form and List any longer.
- Type aware columns for numbers or bool fields will have no measureable effect, as these improvements will happen in the dimension of ns, not µs.
- Caching is difficult, as the dataset can have a lot of dependencies to the current context, for example to user time, localization or tokens
- It is possible to optimize certain types, as the result of API calls can be cached, at least per request (**).
- Joins inside database to populate information about tabs and files makes sense for performance, but it would bypass the public DotNetNuke API. The DotNetNuke Schema is not part of the API and can be changed with every new release – this would not even be a bug, just bad programming. In addition, Form and List datatypes are independent from the module. It is possible to remove, replace or add new data types to Form and List without touching the source of the module.
The downside of the current approach is that filtering happens in a very late state of the rendering pipeline. Therefore filtering and sorting is possible against any column and column type.
Solution might be simple by adding filtering onto SQL server side:
Filter Data on SQL Server → GetData for module → Create a Dataset → Enrich the DataSet →Filter the Dataset → Bind to Output
What I dislike here is that it won't work for every data type, filtering happens twice in the pipeline, both kind of filters will certainly have a different syntax. It is confusing to the users without any background knowledge.
I would like to know what you are thinking about. Shall Form and List offer any additional filter support? Any other ideas?
* Changing of type for fieldvalue from ntext to nvarchar(max) doesn't have any influence on performance, though it makes sense for other reasons.
** In that special case here, where only about 20 different images were repeated again and again, caching reduced the time for image from about 12 seconds down to less a second (18k records).