There was a time when DotNetNuke didn't gather a lot of site statistics. Very early on, we used our own internal site stats features to keep some relevant information but as most hosts know, that architecture is not terribly efficient on a massive scale. But as we have grown and continued to add interactive features to the site ( heavily used forums, active blogs, information repositories, benefactor & vendor management, etc )… our need to understand our site usage at a more detailed level has increased dramatically. So when we migrated to a new web server before the holidays, we finally got around to installing some log analysis software.
Like many organizations, we weren't too concerned about getting indexed. In fact, we’d normally consider it a pretty good thing to get found & indexed when you are still a growing organization in search of broader uptake. But then we took a look at our first week of recorded site traffic…
Oh, my.
So let’s take a look at what we were facing in December. The two screen shots below represent (1) spider traffic on www.dotnetnuke.com and (2) IP traffic. Look at these and let’s see what we can notice.
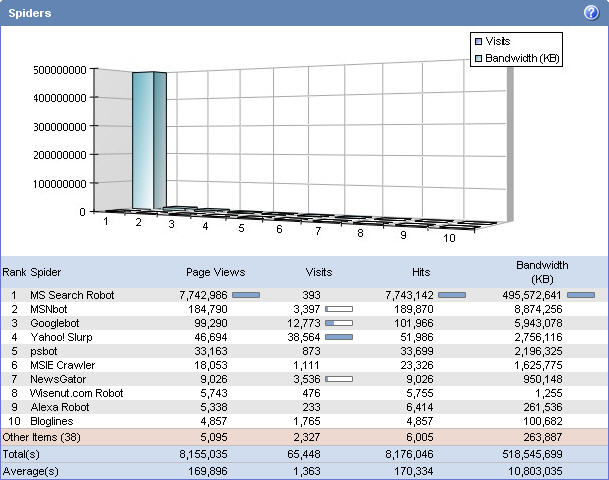
So who’s that “MS Search Robot” that soaked up 495GB of data transfer in December? Not to mention 7 ¾ million page views on 393 visits?
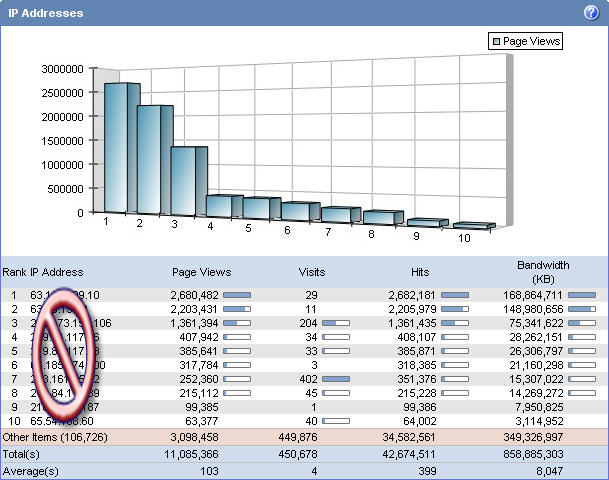
Hmm… and who are those IP addresses with just a few visits and millions of page views… and ( by the way ) responsible for more than half of our bandwidth consumption?
If you go google’ing for “MS Search Robot”… you’re not going to find much except for a bunch of other people asking, “hey, what’s this MS Search Robot”? But if you check your raw server logs it looks a little bit different… “MS Search 4.0 Robot”. Keep digging and you’ll find some obscure references ( mostly circa 2003 ). But the one you’re really looking for is here:
http://support.microsoft.com/default.aspx?scid=kb;en-us;284022#XSLTH3163121123120121120120
You might notice the fine print there…
IMPORTANT: Limit the number of site hops to the absolute minimum number necessary. When you perform an Internet crawl, you might index millions of documents in just a few site hops.
Yep. We can validate that.
Turns out… as we had the opportunity to follow up with some of these IP address owners ( some representing large companies, professional organizations, etc ) we quickly discovered what was happening. All of them were quite happy to work cooperatively with us, often not even aware of the load on their own systems being generated.
Local SharePoint installations ( some development, some production ) were crawling their internal networks. Within their internal networks they had ( one or more ) default installations of DotNetNuke… each of which contains front page links back to www.dotnetnuke.com ( i.e. for the information Links and Sponsors modules ). SharePoint ( without specific inclusions defined ) was just following links… So what else did that fine print say?
The site path rule strategy that is recommended when you are crawling Internet sites is to create an exclusion rule for the entire HTTP URL space (http://*), and then create inclusion rules for only those sites that you want to index.
Oh yeah. Basically that the default settings are a little impolite to other sites and that you should change them. Please make a note. *grin*
Now that we have the proper exclusions in our robots.txt file ( see below )… we’re no longer being hammered by this particular bot. Are you?
User-agent: Mozilla/4.0 (compatible; MSIE 4.01; Windows NT; MS Search 4.0 Robot) Microsoft
Disallow: /